编译器层面优化
编译器默认对代码进行优化。设置gcc编译器优化选项-O1会进行下面的优化:
- 减少循环内的重复计算,把循环内的重复计算提升到循环外
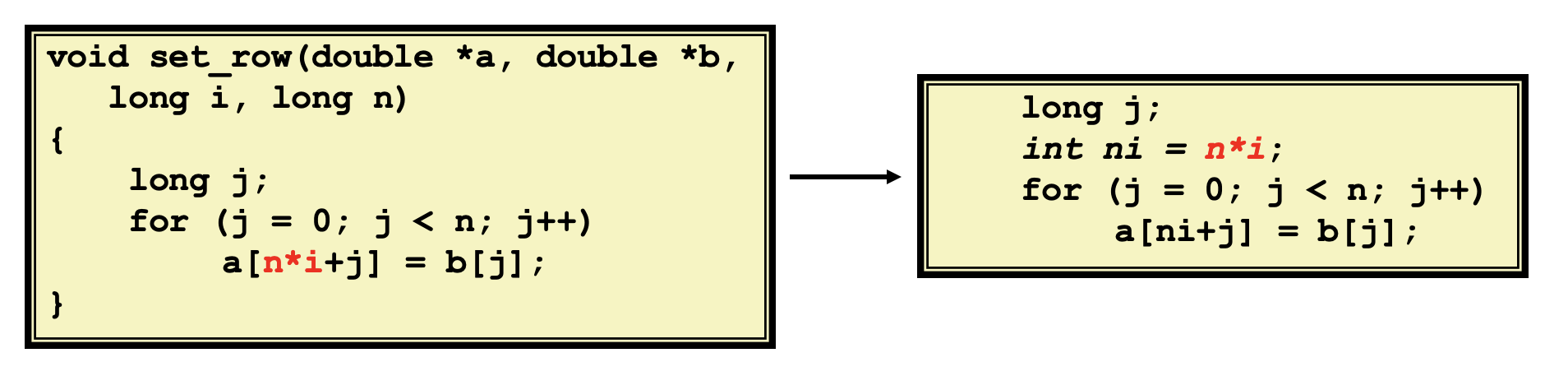
- 乘除法简化,将乘除法转换为加减法,或者将
⨉ 2<sup>s</sup>或/ 2<sup>s</sup>的操作转化为移位
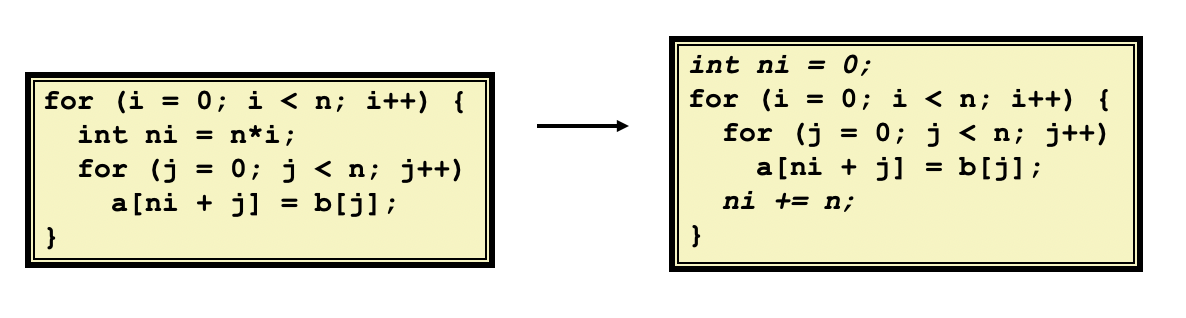
- 提炼共用的子表达式

如果经过上述优化过程后与原来代码不等价,就会取消优化,比如下面的情况:
- 循环内的重复的函数调用

- 重复的内存引用

处理器层面优化
现代处理器不仅通过多个核并行执行代码,而且单个核也有并行执行指令的能力,这个能力称作**指令级并行性(Instruction Level Parallelism)**。单核并行执行指令要求多个指令间的数据不存在相互依赖。
- 超标量处理器:超标量指处理器在一个处理周期内实现处理多次的效果。每条指令可以拆解成多个微指令,比如读取,写入,加法,乘法等。不同的微指令放到专门的功能单元(读取单元,写入单元,加法器,乘法器等)中处理。为了提高这些功能单元的利用率而使它们尽可能忙碌,单个核在一个时钟周期会处理尽量多的指令,把它们的微指令放到不同的硬件单元去。
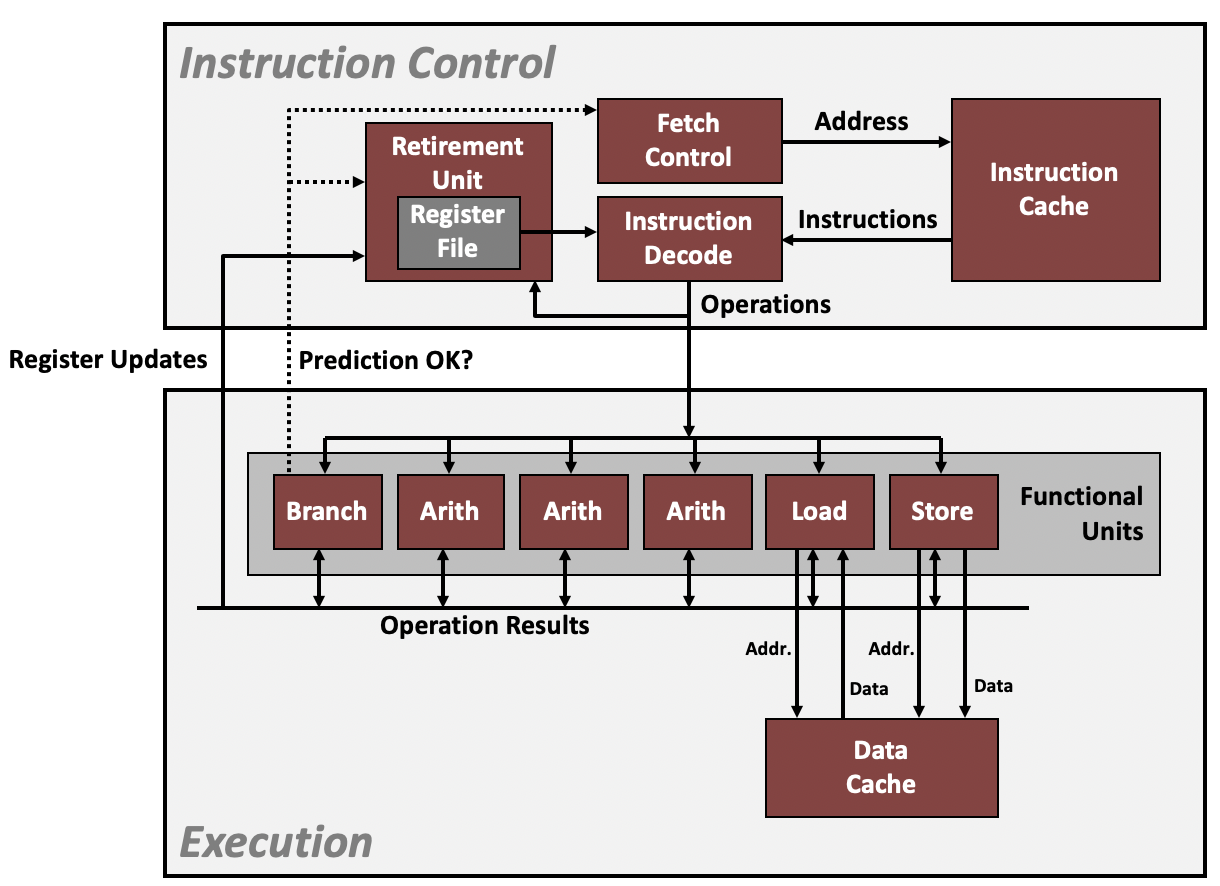
- 流水线设计:对于类似乘法器具有多个执行阶段的功能单元,会尽量使每个执行阶段都是忙碌的。当第一个数据从第一阶段进入第二阶段时,第二个数据紧跟着进入第一阶段。
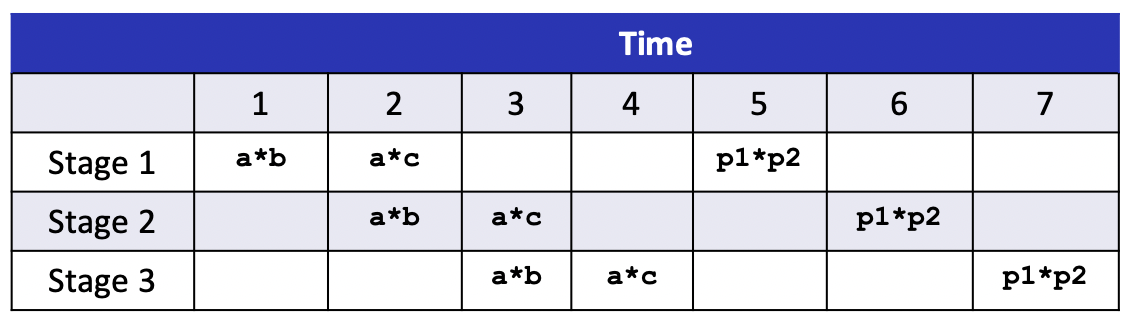
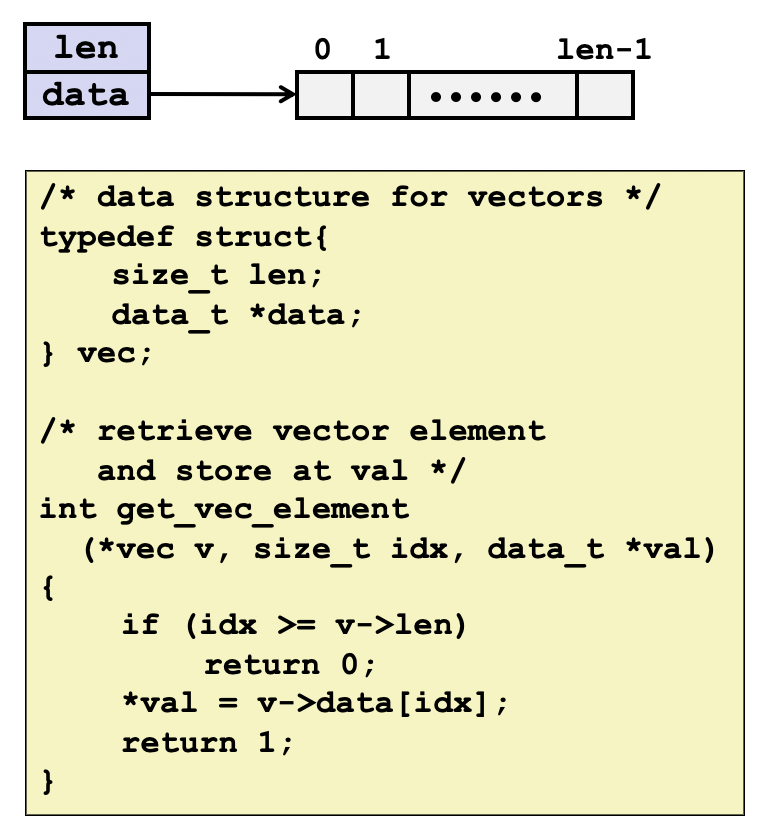
下面以一个程序作为示范,逐步优化该程序的性能。性能测量标准取CPE(操作/时钟周期,Cycle per Operation),那么总的运行时间可以算作T=CPE*n+overhead(其他运行开销)。如果CPE越大,说明指令执行的平均开销越大。根据硬件配置和操作类型不同,CPE存在一个极限,称作延迟界限(Latency Bound),即一个数据被完整处理需要的时间周期。当CPE等于延迟界限时,说明CPU一条接着一条指令执行,完全没有利用处理器的超标量和流水线的特性。这种方式也缩短了计算关键路径。还有另一个代码运行界限——吞吐界限,指充分利用超标量和流水线特性,处理器运行指令的CPE上限。这个界限由处理器中相关的功能单元个数有关,如果功能单元个数越多,那么其超标量执行某种运算的能力越强。下面代码data_t可取值int, long, float和double,OP/IDENT可取值+/0, */1。

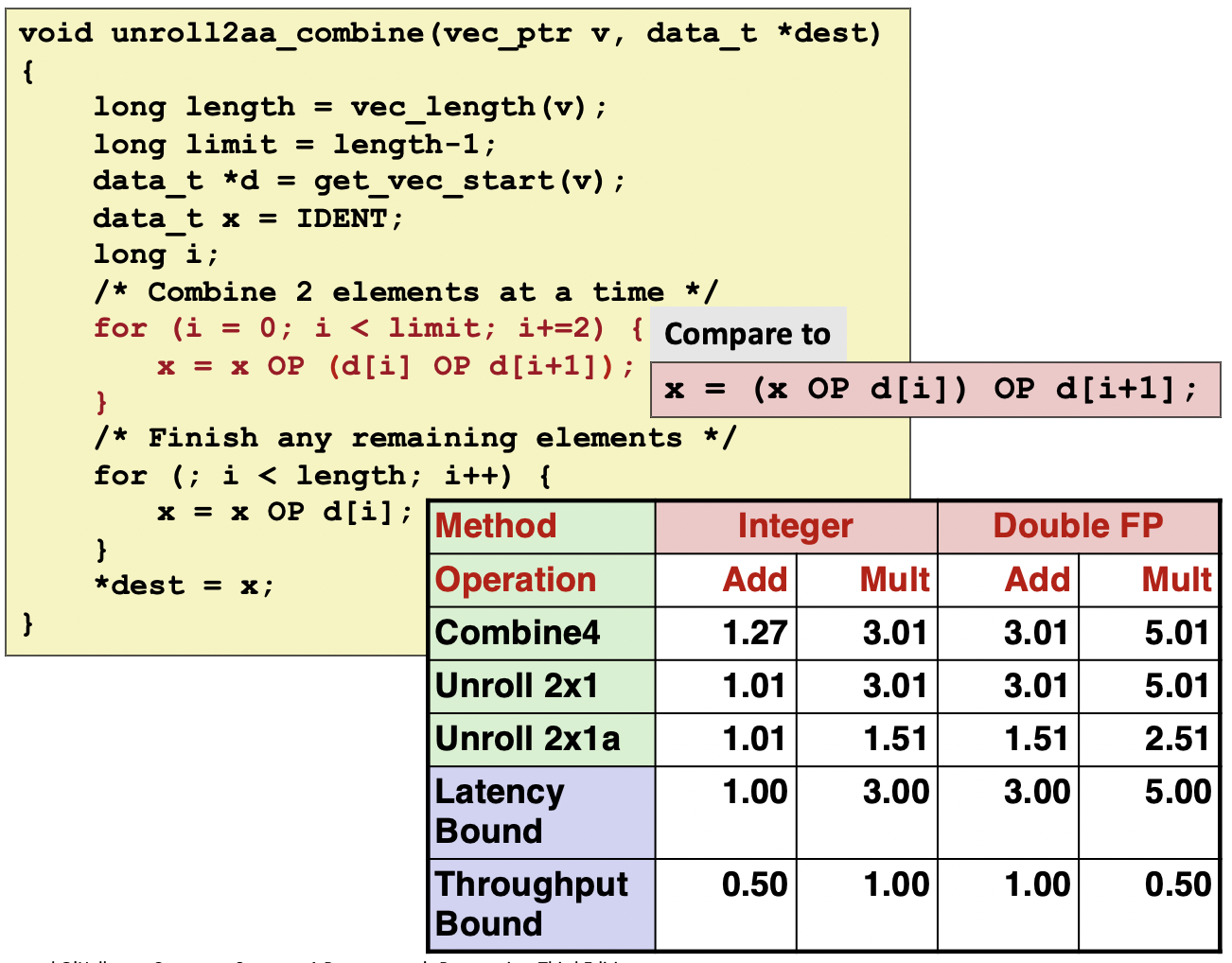
分别对combine关闭和开启编译器优化选项,代码性能大幅提高,但与延迟界限仍有一段距离。
https://i.loli.net/2020/02/04/xW5e8BrPSGCXQoi.png
应用上一节提到的编译器层面优化方法,代码性能已经毕竟延迟界限。接下来的问题是使代码利用现代处理器超标量和流水线特性。
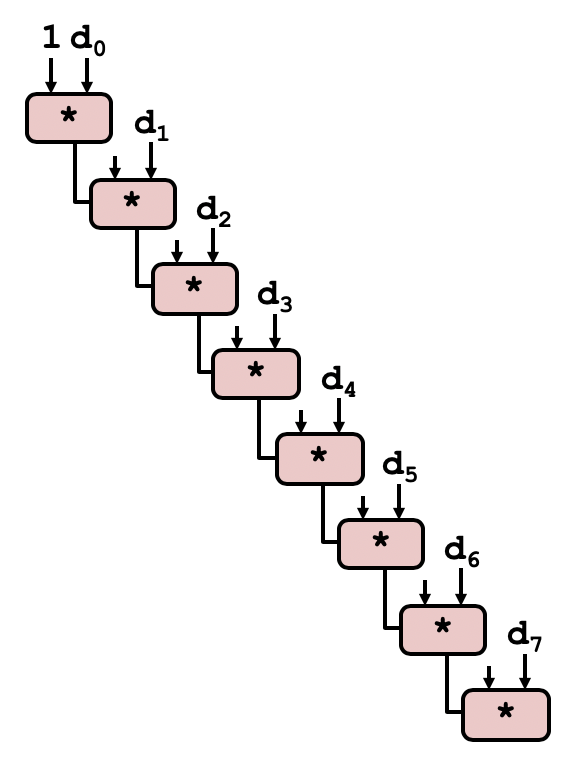
![combine4关键路径]](https://i.loli.net/2020/02/04/tzLi9fkWUGR5dx1.png)
上述代码在每轮循环处理两个元素,但注意元素计算的顺序对性能影响巨大。如果先计算前面两个数据,则计算关键路径与先前无异,所以性能几乎没有提升;而如果先计算后面两个数据,在某轮循环第一次计算与上一轮第二次计算相互不依赖,所以这种方式可以利用流水线的特性。但是对于浮点数,更改元素的结合顺序会改变计算结果。


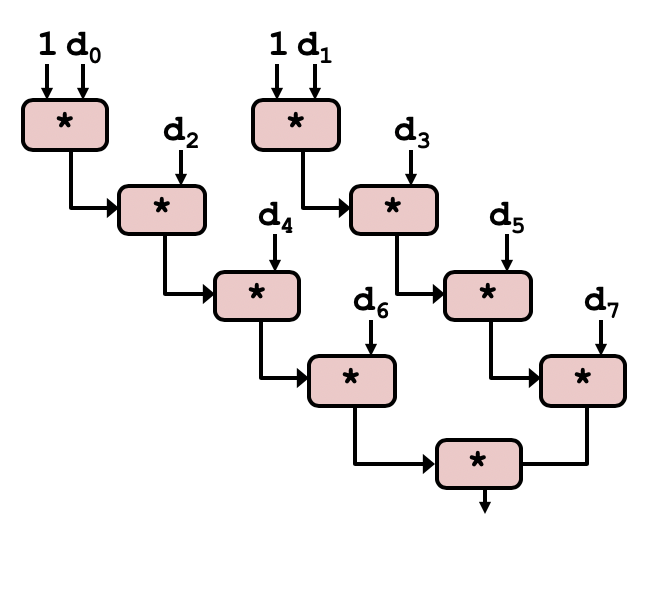
另一种优化方式是计算两个独立的和。通过拆分出多个相互独立的计算过程,可以使CPE进一步逼近吞吐界限。
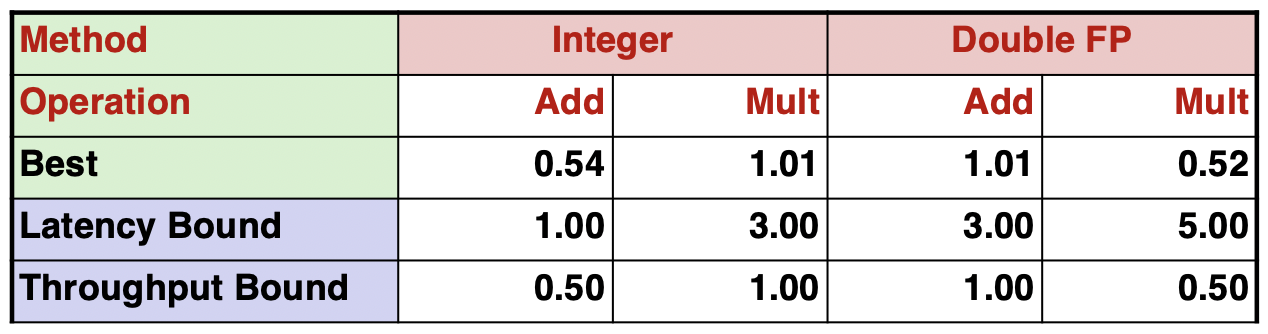
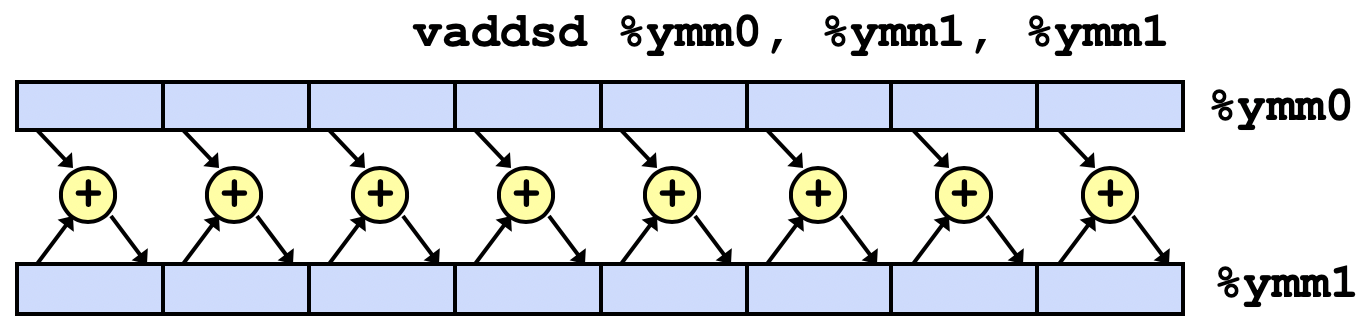
由于浮点数的vaddsd指令可以在一个时钟周期同时计算多个浮点数的加法,理论上浮点数的CPE可以进一步超越吞吐界限。