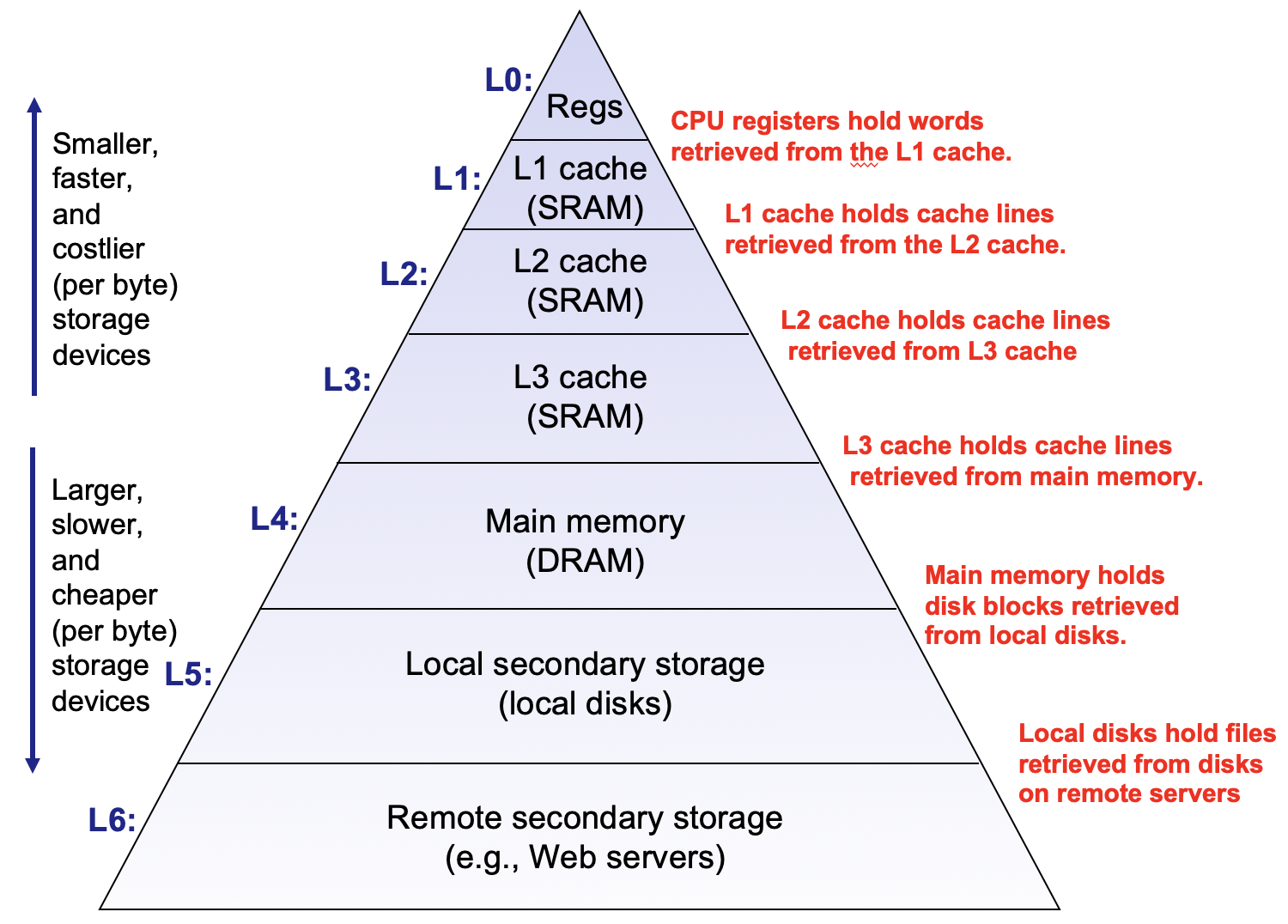
计算机存储体系
不同种类的存储设备往往具有这样的特点:访问速度越快,造价越昂贵,存储空间越小。所以,选取存储设备时存在两个极端,高速设备容量小,而大容量设备速度慢。计算机利用不同种类的存储器,形成一个金字塔式存储体系,意图在两个极端之间达到平衡。金字塔底部,是大容量、慢速、便宜的存储器,比如硬盘,远程文件服务器等,而在顶部,是小容量,高速,昂贵的存储器,比如SRAM,寄存器等。每一级存储设备的访问速度相差巨大,比如访问一次寄存器需要1个时钟周期,L1需要4个,L2需要10个,主存需要100个左右。
缓存
在计算机的存储体系中,每一级(level k)存储设备都是它上一级(level k+1)存储设备的缓存。我们可以将缓存定义为一个存储设备内容的子集。而且,缓存会把数据分作一个个单元,比如高速缓存以块(Block, 64Bytes)**为单位来缓存主存的数据;而主存则一般以页(Page, 4KsB)为单位缓存硬盘的数据。所以,计算机的存储体系实际上是一个多级的缓存系统。需要访问某个地址的数据时,我们到缓存中查找。如果在当前缓存可以找到该数据,则直接返回,这个过程称作缓存命中(Hit)。如果找不到,则去下一级缓存继续查找,直到找到为止,在返回时同时把该数据块更新到当前缓存,这个过程称作缓存不命中(Miss)**。
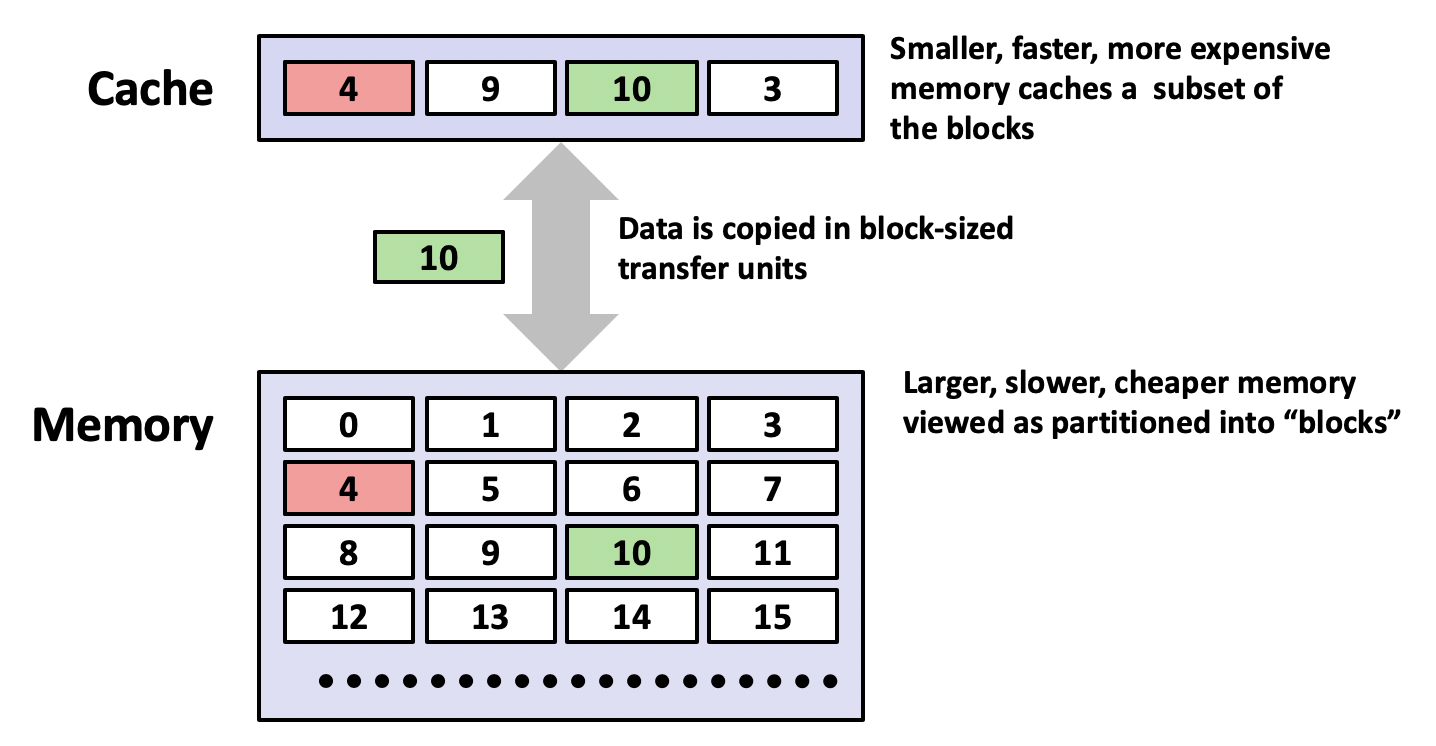
由于每级存储设备间的访问速度差异巨大,缓存不命中的代价会远远超过命中消耗的时间,我们往往将一次不命中的代价平摊到每次访问中。缓存不命中可以分为下面几种情况:
冷不命中(Cold Miss),当缓存为空时,无论访问什么数据都发生不命中。所以我们称程序刚运行时逐步将缓存填满的过程作“热身”;
冲突不命中(Conflict Miss),访问数据的地址映射到一个位置,但是该位置上已经被其他数据占用了,我们把这种不命中称作“冲突不命中”。这时我们根据驱逐策略,用新数据取代缓存中的一个数据块。
读取操作只需要找到所需的数据块,而写入操作还需要考虑何时写入下一级缓存的问题。一般存在两种处理方法:
直写,发生写入时,无论是否在缓存命中,直接写入最底层的存储设备中;
延迟写入,给数据块增加一个更新位(dirty bit),当发生写入操作时设置该位(缓存命中情况);如果缓存中原本不存在该数据块,则按照缓存不命中情况驱逐一个数据块;被更改的数据块在驱逐时才进行写入操作。
缓存示例:高速缓存
高速缓存的属性由C,S,E和B四个参数组成,其中C表示容量,S表示组数,E表示每组的行数,B表示每行的字节数,并满足C=S⨉E⨉B。高速缓存由多个组组成,组由多个行组成,而行由有效位,tag位,和数据块组成,结构如下图所示:
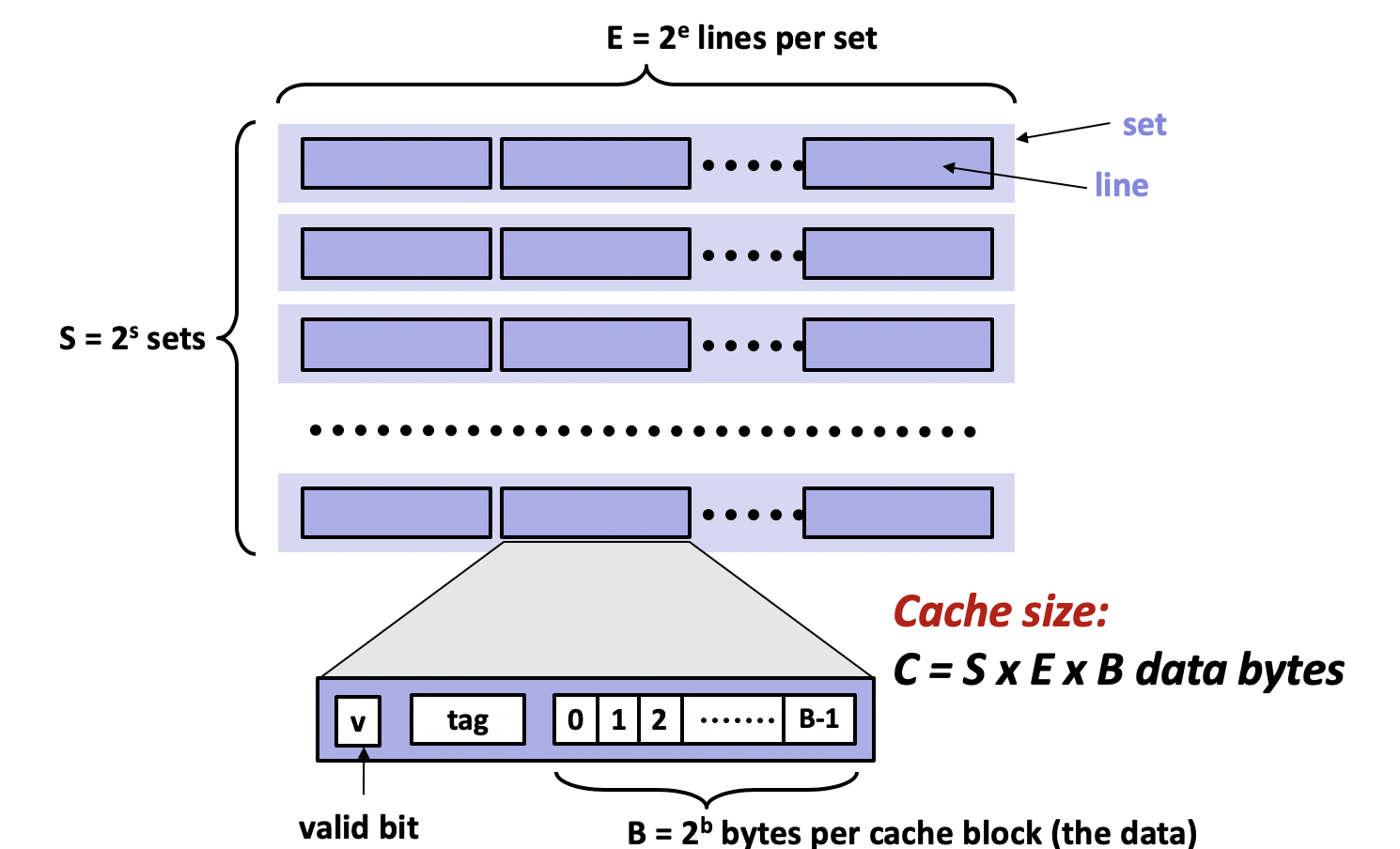
输入一个地址访问数据时,该地址会被分为三个部分,首先根据S和B确定组索引和块索引,最后剩下的部分作为tag。输入地址时,缓存先通过组索引找到组,在组中比对tag找到匹配的行,最后根据块索引找到需要的字节。
缓存局部性原理
缓存的设计基于程序具有局部性的假设,局部性可分为时间局部性和空间局部性:
时间局部性:访问一个变量时,程序在不久的将来会访问同一个数据;
空间局部性:访问一个变量时,程序在不久的将来会访问附近的数据。
正是由于空间局部性假设,缓存以块为单位来存储数据,这样附近的数据也加载到缓存中。可以利用**步长(Stride)**的概念来衡量程序对空间局部性的利用。在最内层循环中,每次访问数据的间隔称为“步长”。我们应当尽量减少步长来增加程序的空间局部性。使用代码测量数据总量对平均每个元素的访问速度的影响,代码使用不同步长读取不同长度的数组,得到下面的实验结果。
long data[MAXELEMS]; /* Global array to traverse */
/* test - Iterate over first "elems" elements of
* array “data” with stride of "stride", using
* using 4x4 loop unrolling.
*/
int test(int elems, int stride) {
long i, sx2=stride*2, sx3=stride*3, sx4=stride*4;
long acc0 = 0, acc1 = 0, acc2 = 0, acc3 = 0;
long length = elems, limit = length - sx4;
/* Combine 4 elements at a time */
for (i = 0; i < limit; i += sx4) {
acc0 = acc0 + data[i];
acc1 = acc1 + data[i+stride];
acc2 = acc2 + data[i+sx2];
acc3 = acc3 + data[i+sx3];
}
/* Finish any remaining elements */
for (; i < length; i++) {
acc0 = acc0 + data[i];
}
return ((acc0 + acc1) + (acc2 + acc3));
}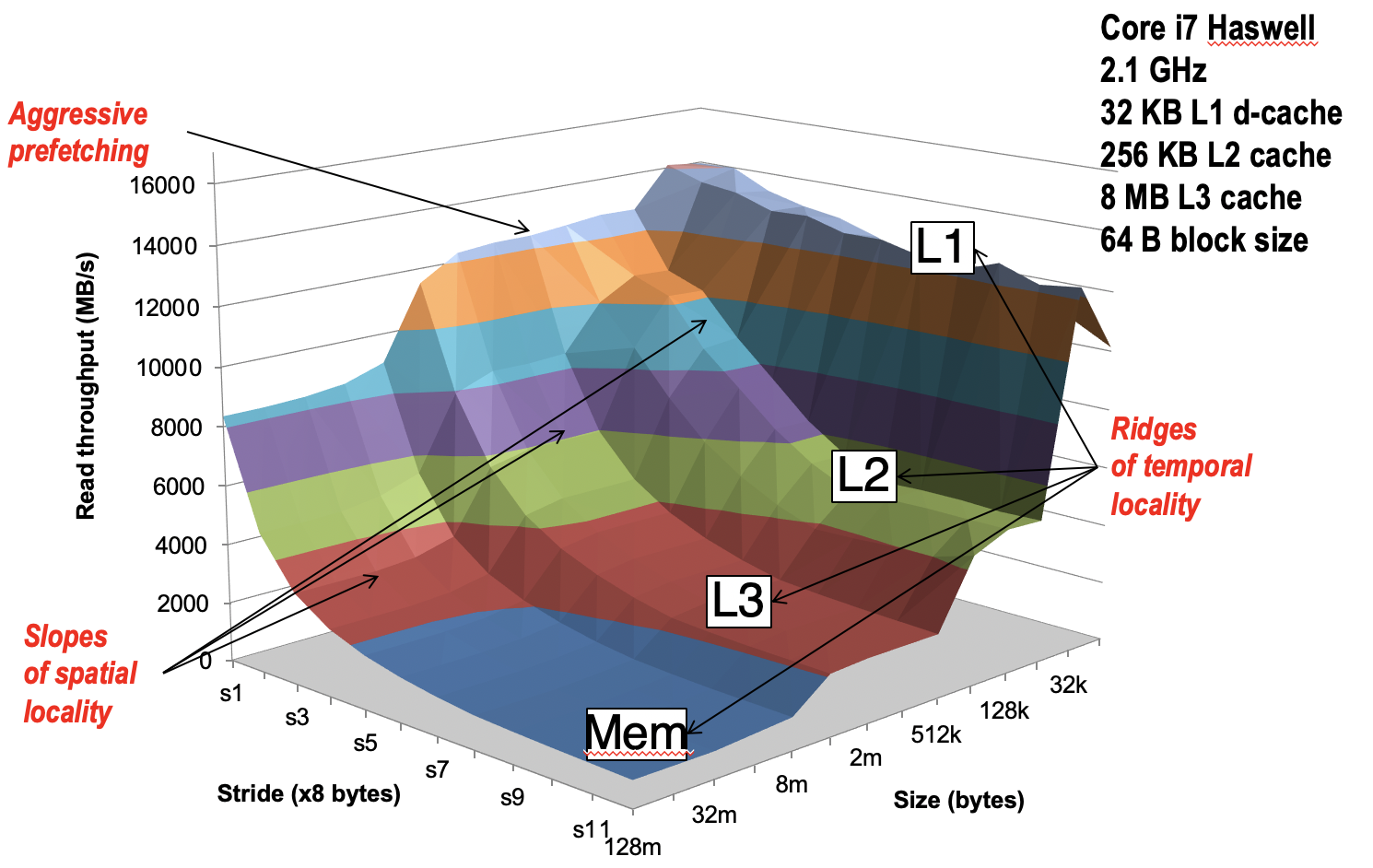
z轴表示数据吞吐量,即数据访问速度,x轴表示数组大小,y轴表示步长。随着数组大小增加,访问速度降低,原因是缓存无法容纳数组,时间局部性降低。随着步长增长,访问速度降低,原因是空间局部性降低。曲面形成类似山脊的形状,在某些地方陡然下降,而在其他位置则是相对平缓的斜坡。实际上,这些相对平缓的斜坡都可以对应到某个存储体系层次,比如斜坡从上到下分别对应L1,L2,L3和主存。当数据量和步长超出该缓存能够容纳的范围时,则出现陡然下降的“山脊”。
优化代码的局部性
增加代码的时间和空间局部性,可以提高程序访问数据的速度,从而优化性能。下面以一个计算矩阵乘积的函数为例来优化它的局部性。
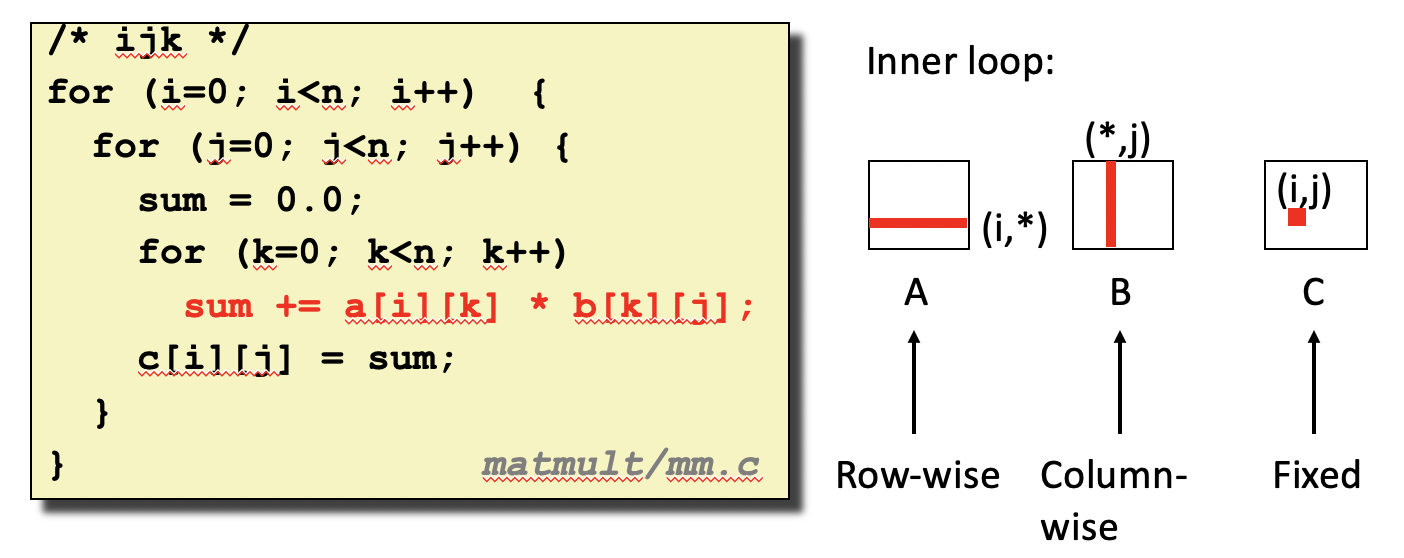
- 交换循环顺序,减小步长
(i, j, k)存在6种排列,不同的排列有不同的步长,不同的空间局部性。上述按照i-j-k的顺序排列,可以计算n✖️n的缓存不命中率(假设缓存块长度为8)
A: nn/8
B: nn
C: 0(不处于最内层循环)
缓存不命中率:5n2/4
矩阵B每个元素都引发缓存不命中,因为访问矩阵B中元素的步长太大。下面的代码按照k-i-j排列循环可以缩小步长:
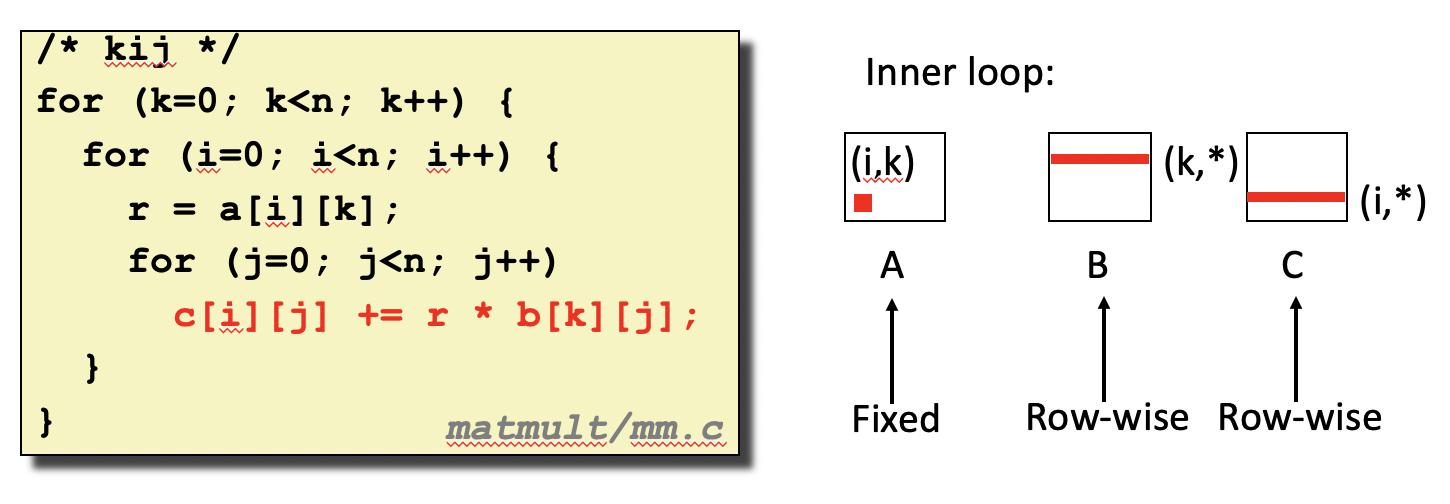
- 分块(Blocking)
计算矩阵C中元素时,矩阵A和B中每个元素都要访问n次。当重复访问矩阵A和B中的元素时,若该元素恰好在缓存中,则提高了代码的时间局部性。将矩阵A,B和C划分为子矩阵可以使得访问矩阵A,B中的元素时,该元素可能已经在缓存中。(假设缓存可以容纳3个子矩阵,即A,B,C各一个子矩阵,且缓存块长度为8)
int i, j, k;
for (i = 0; i < n; i+=B)
for (j = 0; j < n; j+=B)
for (k = 0; k < n; k+=B)
for (i1 = i; i1 < i+B; i++)
for (j1 = j; j1 < j+B; j++)
for (k1 = k; k1 < k+B; k++)
c[i1*n+j1] += a[i1*n + k1]*b[k1*n + j1];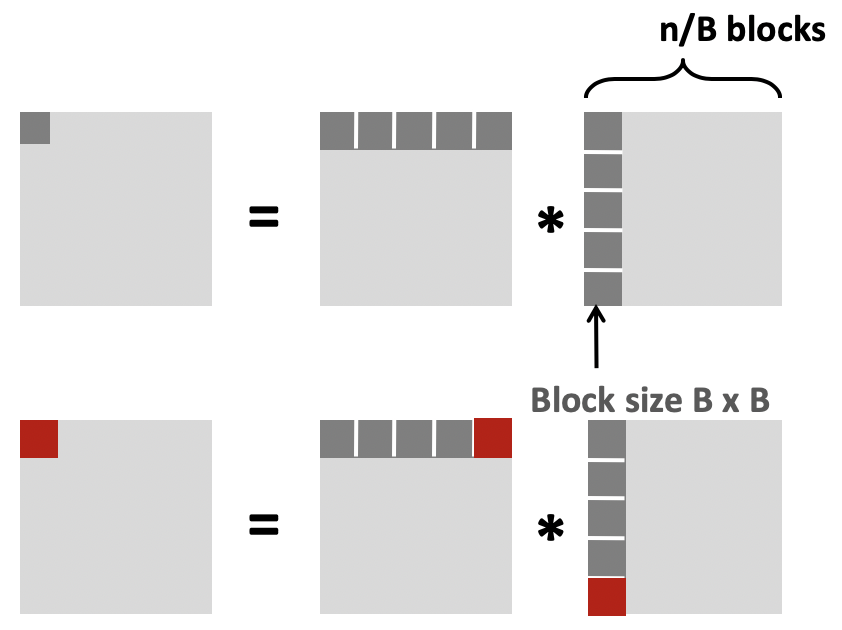
每行: 2n/B * B*B/8 = nB/4
(忽略C矩阵)
缓存不命中率:n*B/4 * (n/B)*(n/B) = n3/(4B)
附:Cache Lab, Part B
Cache Lab, Part B要求优化一个矩阵转置的算法,使得miss的次数尽可能的低。个人认为这是CSAPP所有实验中最难的一个,我在参考了网上的解答才逐步搞明白。所幸的是,这道题只需要针对三种大小的矩阵优化,所以我们针对三个矩阵给出不同的方案。给定的缓存大小是(s=5, E=1, b=5),可以算出缓存大小为1024 Bytes,每一组/行可以存32 Bytes,即4个int。
原始转置函数代码逐个访问A,B中的元素。B纵向访问元素每次访问都会miss,造成很高的miss率。题目提示使用分块(Blocking)减少miss,而问题在于确定分块的大小。
第一个矩阵大小是32x32,矩阵B纵向访问元素,每次步长为32⨉4=128 Bytes,即每次跨越4个组,所以分块大小最大为8x8,刚好填充满整个缓存。
每个分块访问A矩阵的miss率为1/8。而每个分块第一次访问B矩阵时发生8个miss,填充满缓存后,后面就基本可以命中了,分摊后miss率为1/8。在对角线上时,由于地址冲突,每次访问A矩阵时,会驱逐出一个B矩阵的行,所以B矩阵会多出1/8的miss率。非对角线上的块则没有地址冲突的问题。
(1/8 + 1/8) * (16 - 4) * 64 + (1/8 + 1/4) * 4 * 64 = 284
真实实验得出的miss数为287,与计算值贴近。
第二个矩阵大小是64x64,矩阵B纵向访问元素的步长为64⨉4=256 Bytes,每次跨越8个组,分块大小最大为4x4。而大小为4x4的分块不能满足题目少于1300次miss的要求。每次访问矩阵A,B只取4个元素导致了浪费,因为8个元素都会放进缓存中。下面的方法把在8x8的大分块中划分为4个4x4的小分块,重新调整小分块的访问顺序降低miss率。
- 首先,将A的上半部分放入B中,A左上小分块倒置放在B左上角,A右上小分块倒置放在B右上角。A的miss率为1/8;如果在对角线上,由于地址冲突,除了第一次读取B的元素,A还会额外将B驱逐一次,B的miss率为1/4,否则B的miss率也为1/8。
8 * 32 * (1/8 + 1/4) + (64 - 8) * 32 * (1/8 + 1/8) = 544
- 第二步,将B的右上小分块转移到B的左下角,A的左下倒置放在B右上角。由于上一步结束,缓存中还保存了B的右上角,所以访问B的miss只发生在左下角,对角线上的miss率为1/4,非对角线上的miss率为1/8;A的miss率为1/8。
8 * 32 * (1/8 + 1/4) + (64 - 8) * 32 * (1/8 + 1/8) = 544
- 最后一步,将A的右下小分块倒置放在B的右下角。上一步访问B的左下角也会缓存B的右下角,所以对角线上B的miss率为1/8,非对角线上B的miss率为0;A的miss率为1/4。
8 * 32 * (1/8 + 1/4) = 96
合计为1188,实际为1227次。
第三题是大小为61x67的不规则矩阵。由于要求比较宽松(4087个元素要求最多2000次miss,相比上一题4096个元素要求1300次miss),通过试验,16x16的分块就可以满足要求。