物理内存和虚拟内存
虚拟内存(Virtual Memory)**可以看作磁盘与DRAM主存之间的缓存,也可以看作物理内存(Physical Memory)与进程/操作系统间的视图,起内存管理的作用。我们使用地址空间(Address space)**来描述物理内存和虚拟内存两种不同的概念。地址空间是由从1开始连续的整数组成的集合{1,2,3,…,N},那么虚拟内存和物理内存则分别用两个不同的地址空间描述:{1,2,3,…,V}和{1,2,3,…,P}。虚拟内存的作用主要有下面三点:
缓存作用,提高访问主存的效率
简化内存管理
内存读写保护,进程间内存空间相互隔离,进程无法访问内核内存
作为缓存的虚拟内存
64位机器的虚拟内存大小为248,地址空间远大于物理内存,所以物理内存实际只能保存虚拟内存一部分内容。使用高速缓存的结构来理解虚拟内存,只有一个组,组内是全相联的。如高速缓存,虚拟/物理内存数据被划分成块,内存中的块称作**页(Page)**,页的大小一般是4KB~4MB。页大小远超过高速缓存块大小的原因是,页缓存不命中的代价(访问磁盘数据)比高速缓存块缓存不命中大得多,所以扩大页的大小分摊缓存不命中的代价。除了使页更大,虚拟内存还采用了延迟写入和更复杂的驱逐算法来尽量减少访问磁盘的次数。虚拟内存的替换算法远比高速缓存中(LRU)复杂,因为花费时间寻找驱逐页的时间远小于缓存不命中付出的代价。
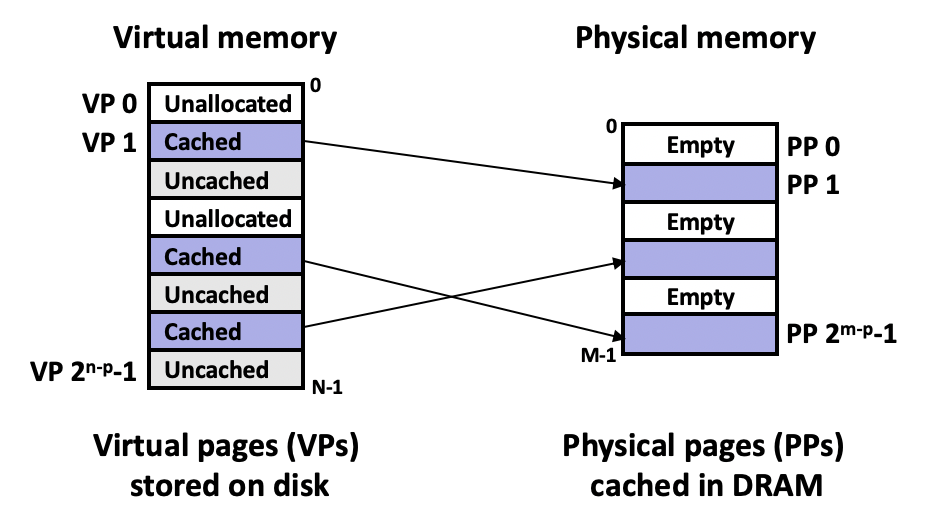
下图中,虚拟内存中的页分为Cached,Uncached和Unallocated三个状态。Cached指该页已经被缓存到物理内存,存在一个指向物理内存地址的映射;Uncached指未被缓存;Unallocated指该页在虚拟内存上未分配。
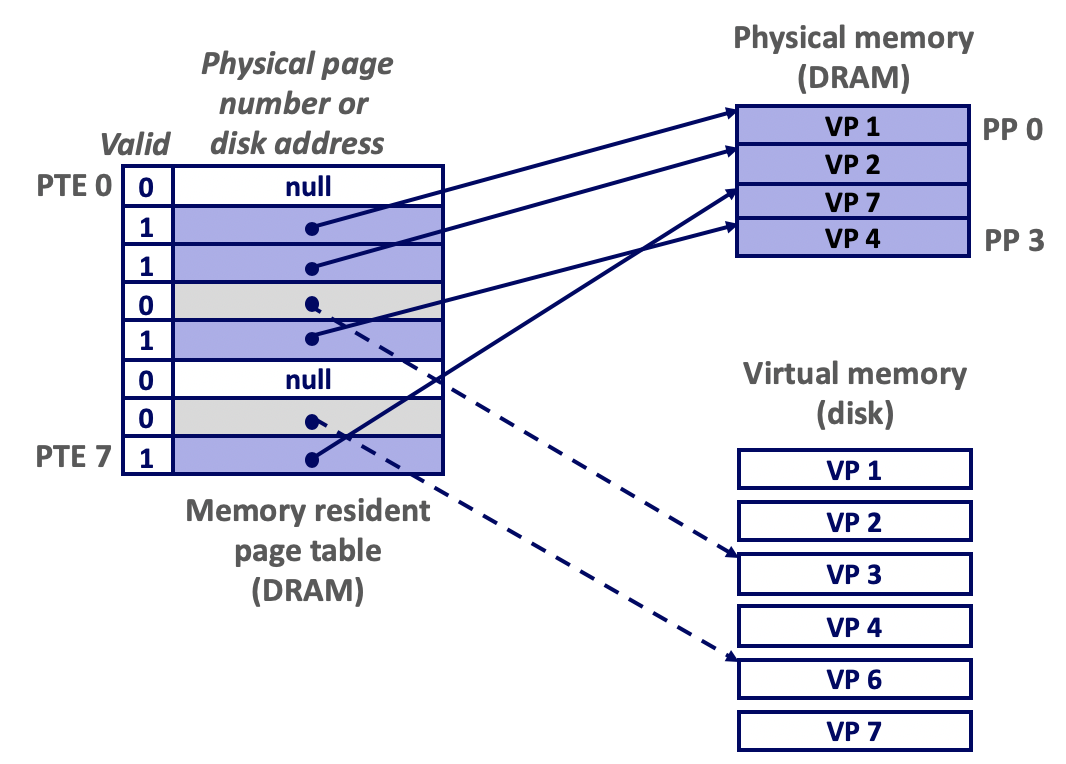
操作系统使用页表(Page Table)**来存储虚拟内存页地址到物理内存页地址的映射,页表以虚拟内存地址作为索引,条目内容是物理内存的地址,条目被称作页表项(Page Table Entry, PTE)**。看下图,每个页表项有一个Valid位记录该页是否缓存,还有一个指针在缓存时(Valid=1)指向物理内存地址,在未缓存时(Valid=0)指向磁盘地址。所以,当处理器访问某(虚拟)内存的地址时,需要通过页表来获取真实的物理地址。处理器使用虚拟地址作为索引,在页表中获取对应页表的页表项,如果Valid设置为1,则缓存命中,可以直接到物理内存获取数据;否则,缓存不命中引发缺页故障,操作系统选择一个驱逐页,用磁盘中的页来替换。如果该页表项是Unallocated(Valid=0且指针为null),则引发段错误。
实际上,虚拟内存作为缓存,也利用了程序局部性的原理。在一段时间内,程序频繁访问的一组页面称作**工作集(Working Set)**。如果物理内存可以容纳整个工作集,系统就能达到较好的内存性能。
作为内存管理工具的虚拟内存
在虚拟内存出现以前,系统把物理内存划分成固定大小提供给进程,每次进程加载到内存中的位置都不一样。而虚拟内存出现后,每个进程都拥有独立的虚拟内存空间。虚拟内存为进程提供了统一的视图,即{1, …, 248-1}的地址空间,实际上进程的数据可能分散在物理内存中的各处,或者多个进程共用的共享库代码和数据都放在同一页物理内存中,但系统为进程管理了虚拟内存到物理内存的映射。
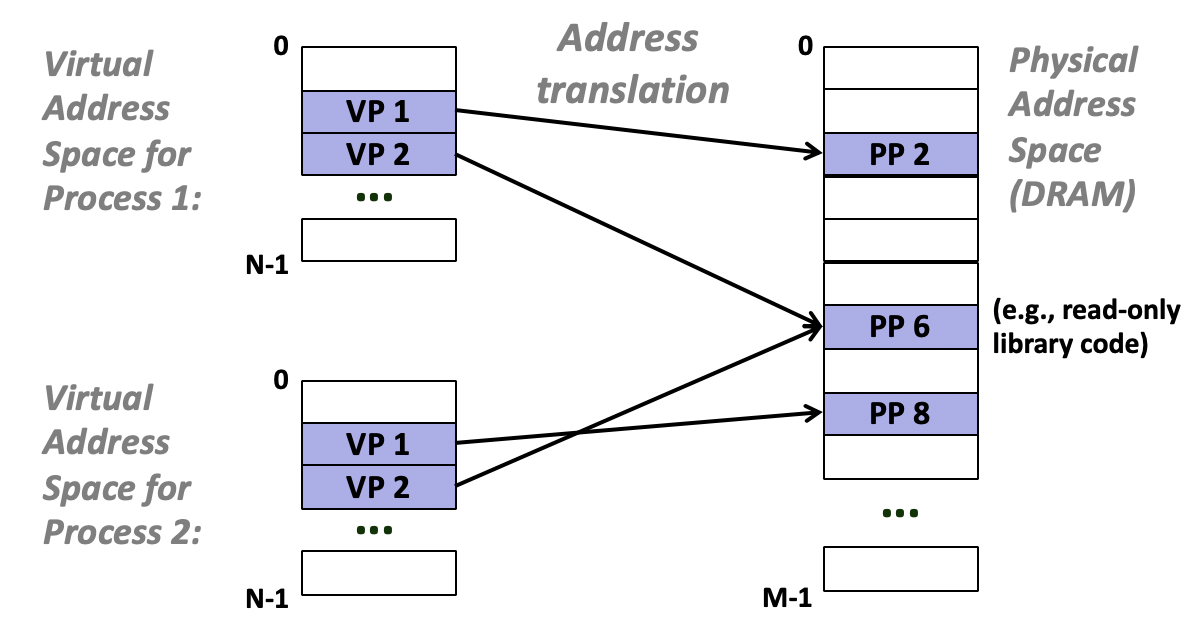
虚拟内存也简化了程序的链接和加载。由于虚拟内存提供的统一视图,链接器生成二进制目标文件时总是把.text,.data等区段放到同一个地址。而execve函数加载二进制可执行文件时,只需要重新生成页表,把Valid设置为0,指针指向磁盘中该文件的位置,然后把%rip设置为代码段第一条指令的地址,而不需要亲自从磁盘中加载该文件的内容。因为处理器读取%rip指令会引发缺页故障,在缺页故障处理程序中才执行加载操作,其他数据也是如此,实现了延迟按需加载。
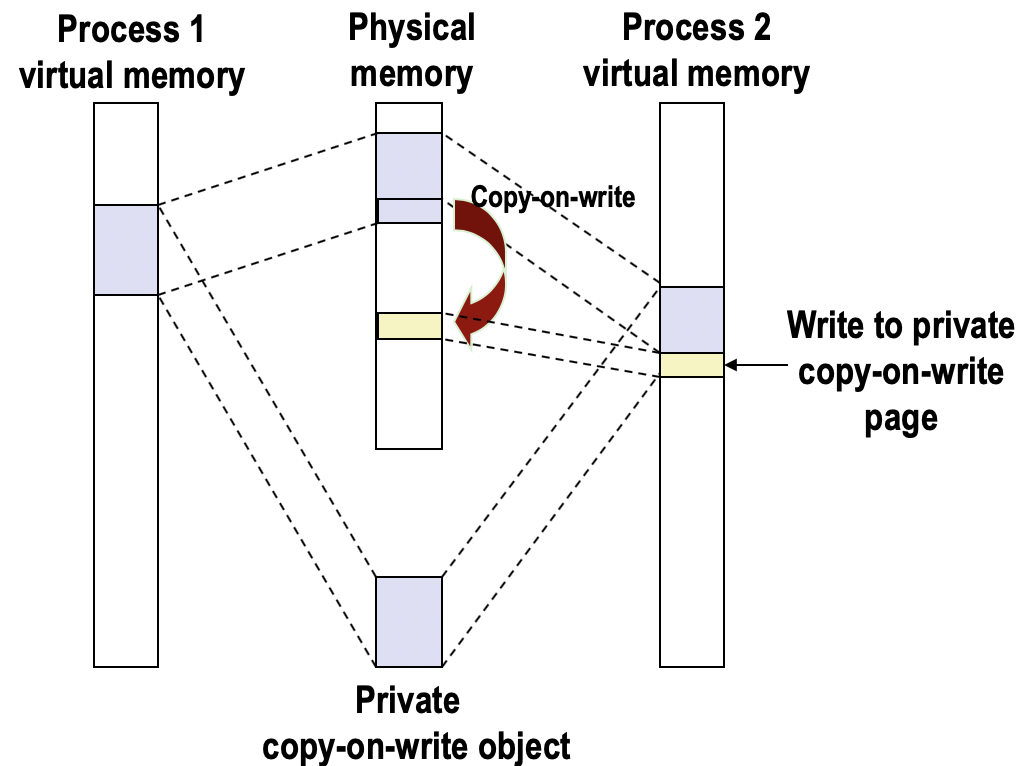
fork函数创建一个与父进程一模一样的子进程。实际上,fork函数只是重新创建了页表,页表项指向与父进程一样的物理内存页。所以fork函数返回时,子进程与父进程拥有相同的数据和进程状态。当子进程向某虚拟内存页写入时,操作系统为子进程复制该页。这种延迟复制的策略叫作复制时写,提高了内存的利用率。
提供内存保护的虚拟内存
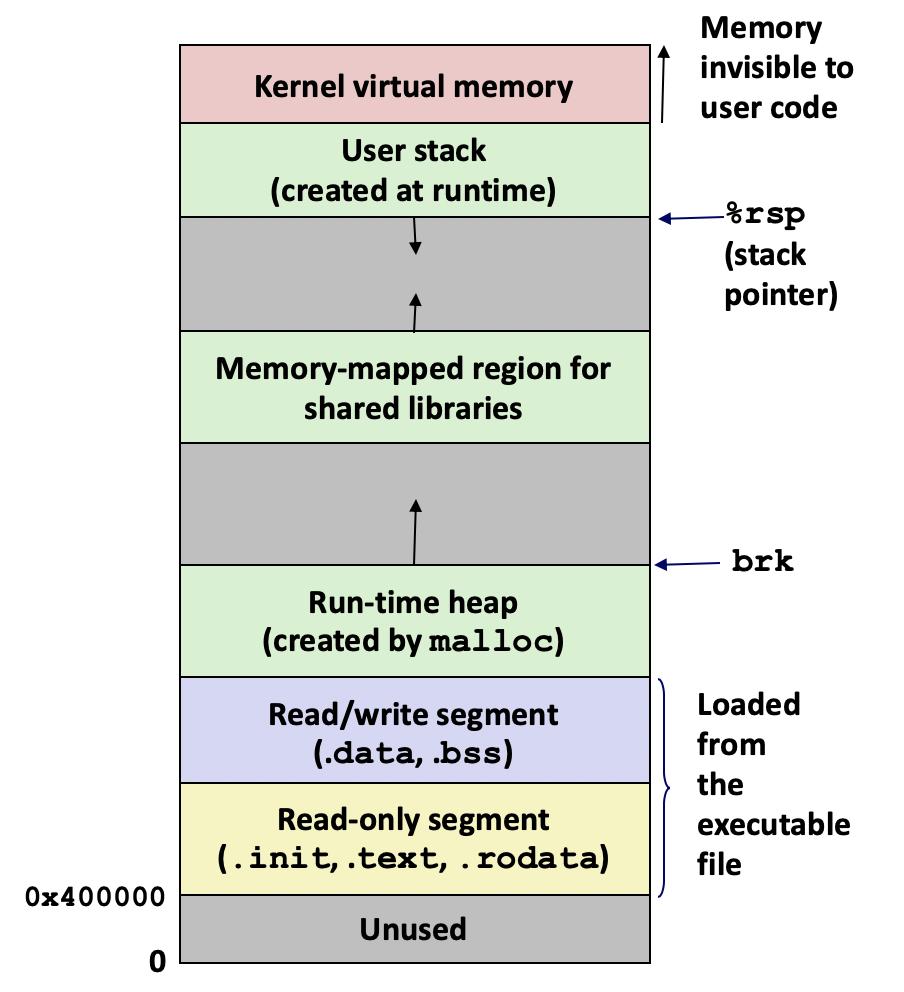
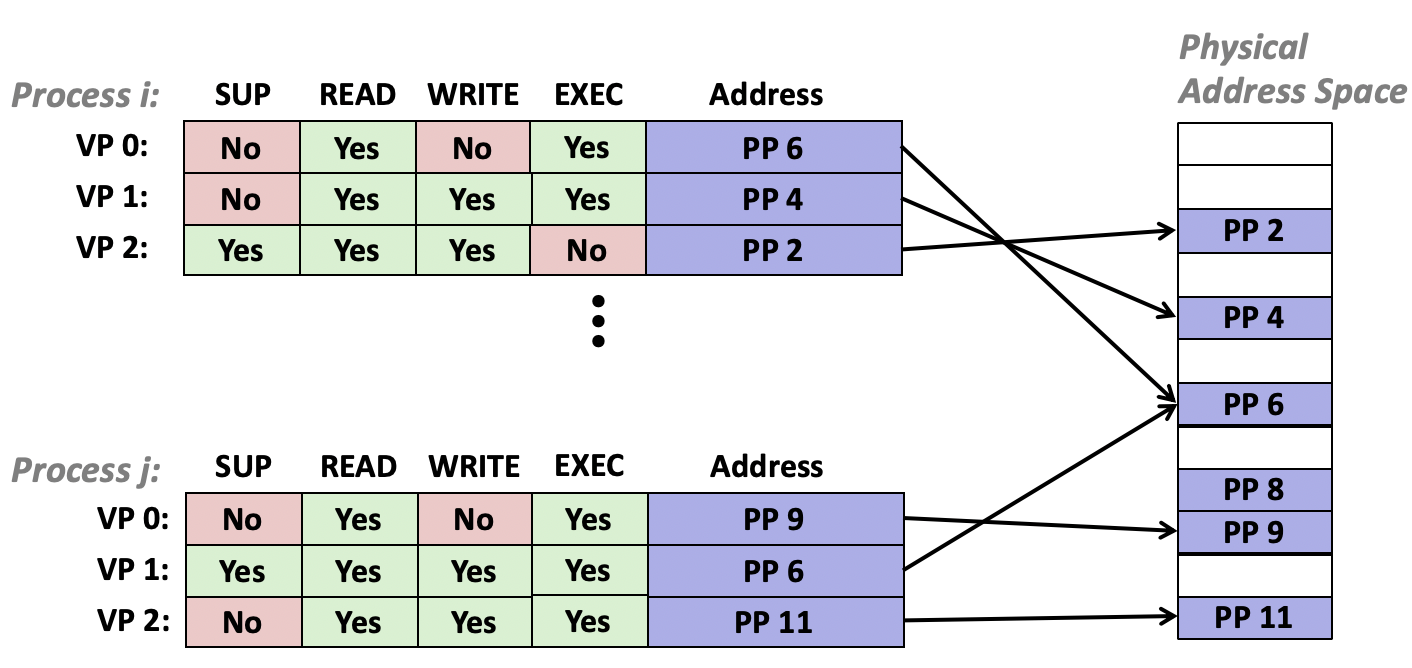
x86-64的地址一共有64位,但只有48位可用,剩下的高16位要么全1,要么全0。如果地址高16位全为1,则访问的是内核中的代码和数据。可以在页表项中添加额外的位控制地址的访问权限,比如读写,执行,内核等权限。为内存中的数据区域,如堆栈,设置执行权限可以防止代码注入攻击发生。
虚拟内存的地址翻译
CPU芯片中CR3寄存器存储页表的基地址。MMU是专门用于翻译地址的器件。为了加速MMU地址翻译的过程,CPU芯片中还有一个器件缓存了虚拟地址对应的物理地址,称作TLB。处理器把虚拟地址发送给MMU,MMU先尝试从TLB获取物理地址,如果缓存不命中则到内存中获取。获取页表项后,就可以计算出物理地址了。如果物理地址是有效的,则到内存中获取数据返回给CPU,否则引发缺页故障或段错误。
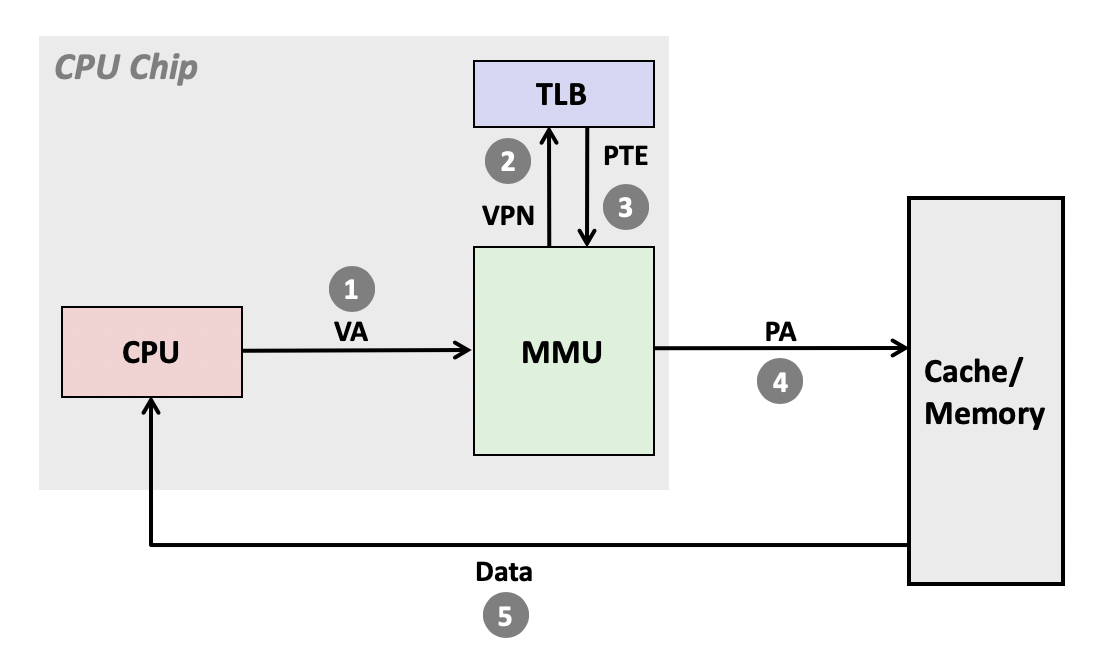
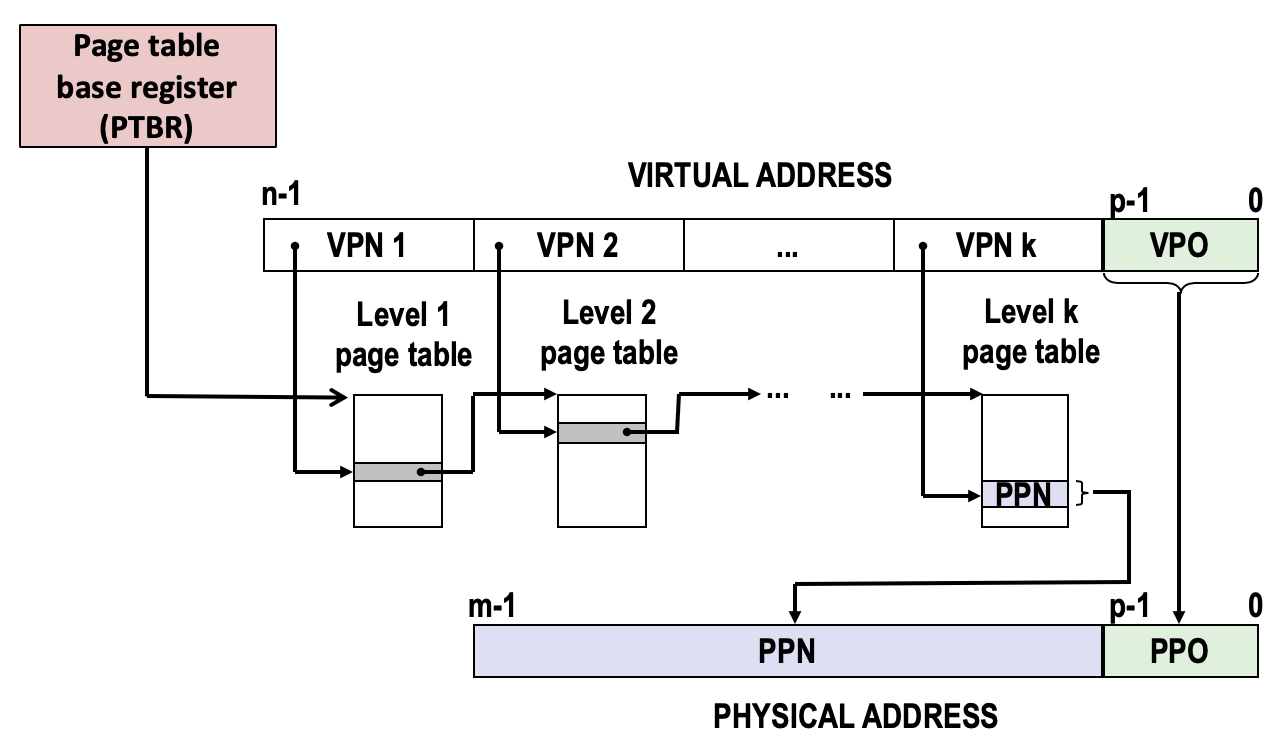
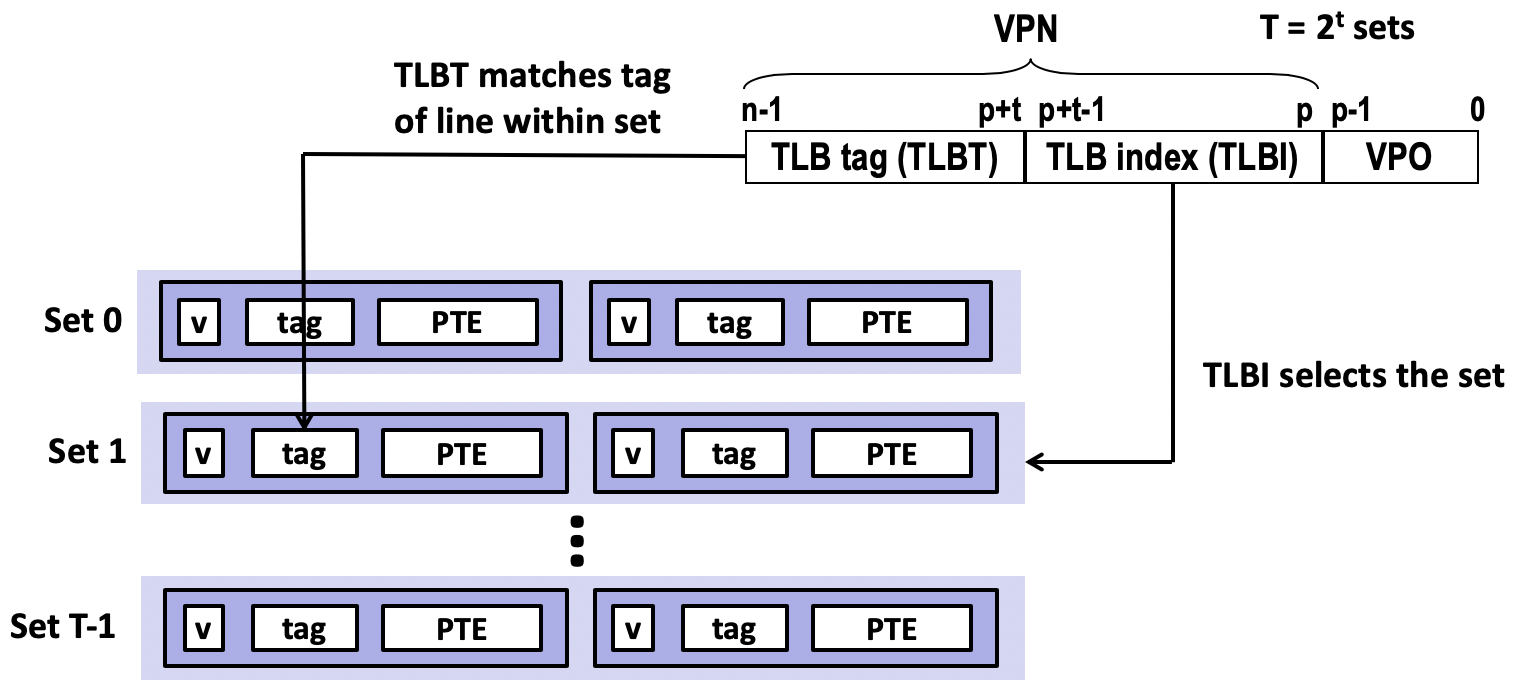
我们使用缓存结构来理解虚拟内存的地址翻译过程。虚拟内存和物理内存的地址可以分别划分为VPN和VPO,PPN和PPO。其中VPO和PPO完全一致,而VPN是页表的索引,也用于在TLB检索物理地址的PPN。TLB的工作原理与高速缓存一致,也分为组和行,只是行的内容是一个物理地址的PPN,用于检索的VPN被进一步拆分为TLBT和TLBI作为tag和组号。获取到PPN后,与VPO进行组合,就得到了物理地址。
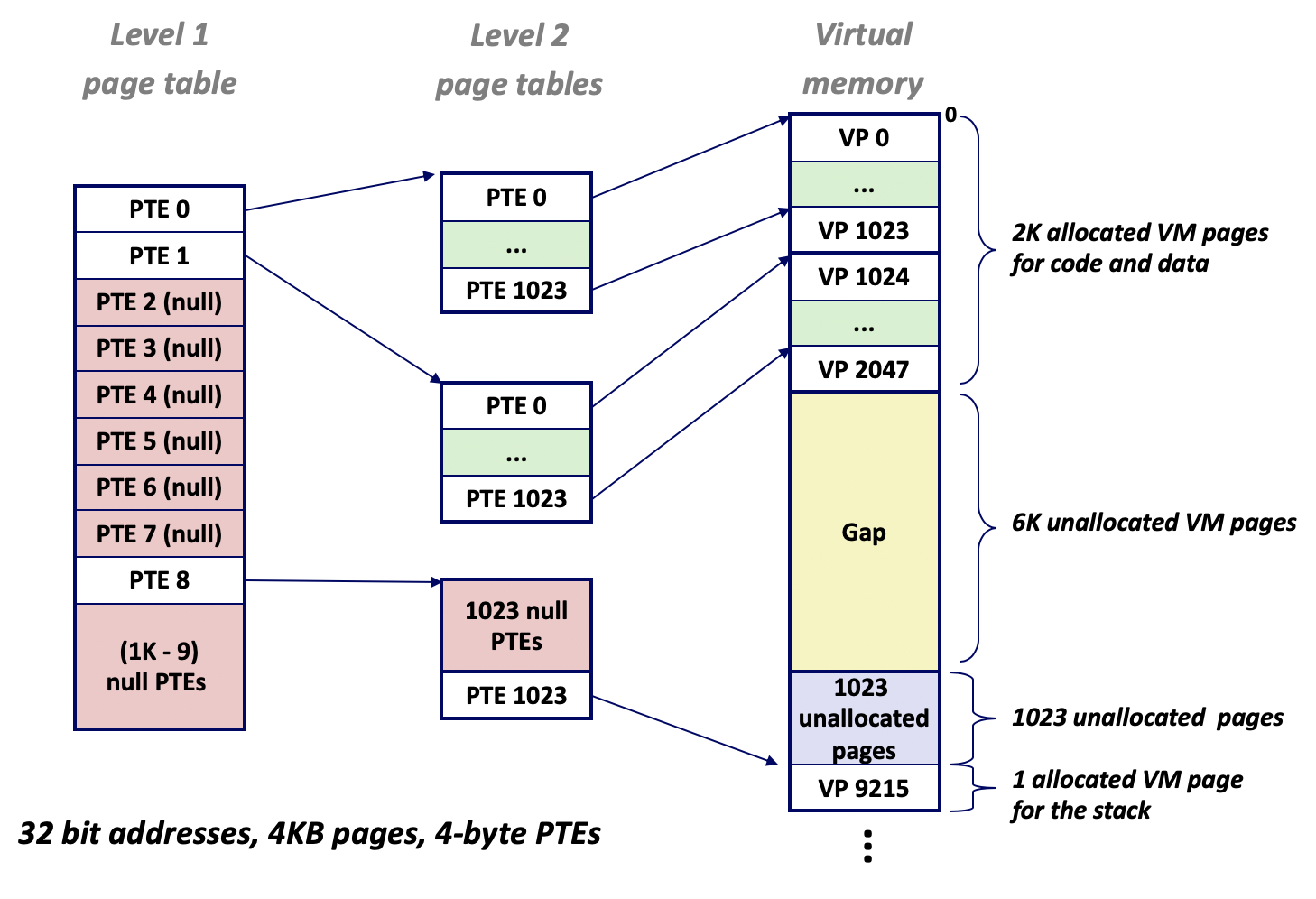
假设每个页表项需要8 Bytes,页长4KB,那么VPO长度为12位,VPN长度为36位,那么仅一个进程的页表就需要占用512GB空间!这样显然不可行。所以,引入了**多级页表(Multi-level Page Table)**来解决这个问题。多级页表的翻译过程经过了多个页表,每个上级页表记录下级页表的基地址,最后一级页表才记录物理地址的PPN。虚拟地址VPN也被划分为多段,VPN1,VPN2,…,分别是各级页表的索引。比如一个二级页表,每个页表有1k个页表项,每个二级页表项对应一个4KB的页,那么每个一级页表项则对应4MB的内存区块。虚拟内存中的大部分内存都处于未分配状态,连续4MB的内存区块只需要在一级页表项写入null,可以节省分配给二级页表的空间。多级页表的级数越多,则可节省的空间越多。