并发模型
常见有三种并发模型:
基于多进程
利用I/O复用技术的事件驱动
基于多线程
多线程的概念模型
理论上,多个线程共享进程上下文环境(代码段,数据段,堆和共享代码库等),但各自拥有独立的寄存器和**线程栈(thread stack)**。但是实际上,该概念模型并不严格成立,比如一条线程可以通过全局变量或传参间接地访问另一条线程的本地数据。所以,无论全局变量或本地变量,都可能成为共享数据。而并发访问的共享数据,存在一致性的问题,导致程序每次运行结果不同,因为线程访问没有受到保护的数据,一条线程在读写数据的两个操作中间,数据已经被另一条线程更改。
并发访问一个典型问题是**竞争(Race)**。该问题可能发生在多条线程,一边在读,一边在写情况,则无法确定读线程访问到的是写前的值,还是写后的值。
下面介绍解决并发问题的措施。
信号量
信号量(Semaphore)**是一种同步机制。信号量可以表示系统中某种的资源的数量,存在P和V两种操作,前者用于消耗资源,后者释放资源。需要消耗资源时,如果没有资源则阻塞等待其他线程释放资源。使用信号量可能导致死锁(Deadlock)**问题,即两条线程相互等待对方释放资源。解决死锁的办法是使用同种顺序上锁,解锁。
下面介绍依赖信号量实现的两种并发模型。
生产者-消费者并发模型(Producer-Consumer)
生产者和消费者是两种类型的线程。两者共享一个缓冲队列,生产者往队尾中插入数据,消费者从队头消耗数据。维持这样的模型需要三个信号量来确保数据的一致性,mutex,items和slots。mutex是访问缓冲区共享变量的锁,比如操作head,tail等;items表示缓冲区数据的个数,是消费者消耗的资源;slots表示缓存区空位的个数,是生产者消耗的资源。
生产者-消费者并发模型可以用于服务器的设计。比如接收连接的主线程是生产者,处理客户端数据的是消费者。那么生产者在连接成功后,只需将连接(比如文件描述符)放入缓冲队列,消费者从中取出连接进一步操作。可以提前分配一定数量的线程,这种模型称为线程池。
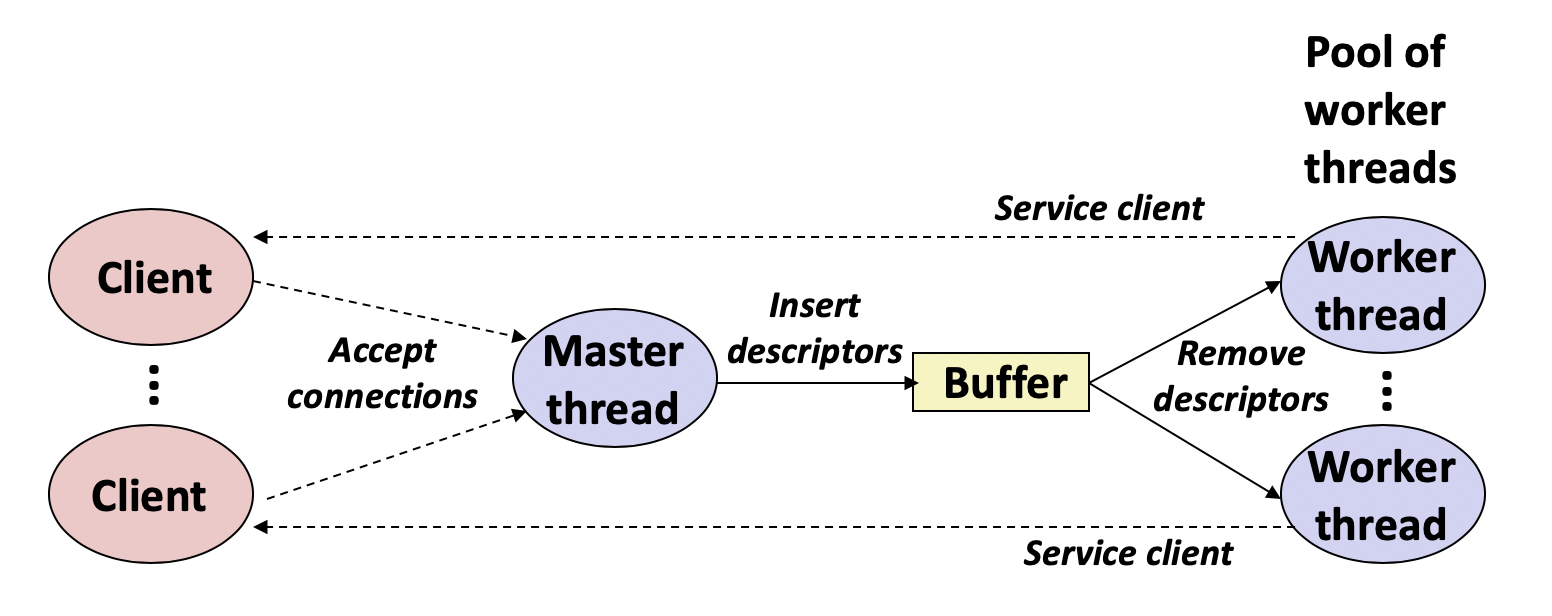
并发读写问题(Readers-Writers Problem)
并发读写问题中存在多个读写某个资源的线程,要求多个线程可以同时读,但是只能一个线程独占的写。该问题需要考虑优先级,如果读线程的优先级高,那么尽管有写线程在等待,后来的读线程也会插队,可能导致写线程一直等待(饿死,starvation);反之,如果写线程的优先级高,后来的写线程将插队到读线程的前面,可能导致读线程饿死。
线程安全函数
另一个解决并发问题的方法是只在线程中使用**线程安全函数(thread safe functions)**。线程安全函数定义为多个线程同时调用也总是能获得正确的结果。前面信号介绍的可重入函数是线程安全函数的一个子集。因为只使用本地变量(栈上数据)的可重入函数也是线程安全函数。
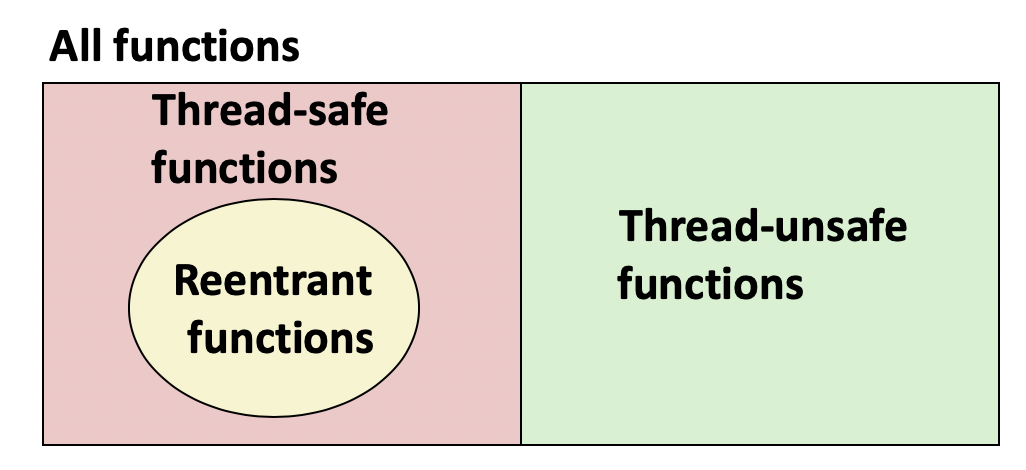
而线程不安全的函数有下面4种情况:
- 未上锁访问共享变量;
解决:上锁。
- 在内部保留状态的函数,比如
rand函数生成的随机数依赖上一次产生的值,多线程并发调用则不能保证相同的种子(seed)产生相同的伪随机数序列;
解决:手动传入上一次随机数的值。
- 返回一个指针指向局部静态变量的函数,比如
ctimes函数返回一个指针指向内部static变量,该变量保存了实时更新的时间,多线程并发访问线程相互之间会窜改返回值;
解决:手动传入缓冲变量,将static变量的值复制到缓冲中。
- 调用了线程不安全函数的函数。
解决:不要调用。
多线程性能优化
如果比较当下市场最好的多核和单核处理器 ,多核处理器运行多线程,单核处理器运行单线程,性能差距可能并没有那么大。因为多线程存在线程调度,同步机制的额外花销。多线程的性能也大大依赖程序的写法。下面介绍一个多线程对{1,…,n}求和程序的优化过程。
第一个版本用一个全局变量记录和,每轮循环上锁访问全局变量。可以料想,这个程序因为频繁的上锁,性能不会太好。
/* Thread routine for psum-mutex.c */
void *sum_mutex(void *vargp)
{
long myid = *((long *)vargp); /* Extract thread ID */
long start = myid * nelems_per_thread; /* Start element index */
long end = start + nelems_per_thread; /* End element index */
long i;
for (i = start; i < end; i++) {
P(&mutex);
gsum += i;
V(&mutex);
}
return NULL;
}
可以看到,坏的程序在多线程情况下性能比单线程还更差了。第二个版本把线程的结果保存在各自独立的全局变量中,主线程等待所有线程执行完后,再对所有结果进行求和。
void *sum_array(void *vargp)
{
long myid = *((long *)vargp); /* Extract thread ID */
long start = myid * nelems_per_thread; /* Start element index */
long end = start + nelems_per_thread; /* End element index */
for (i = start; i < end; i++) {
psum[myid] += i;
}
return NULL;
}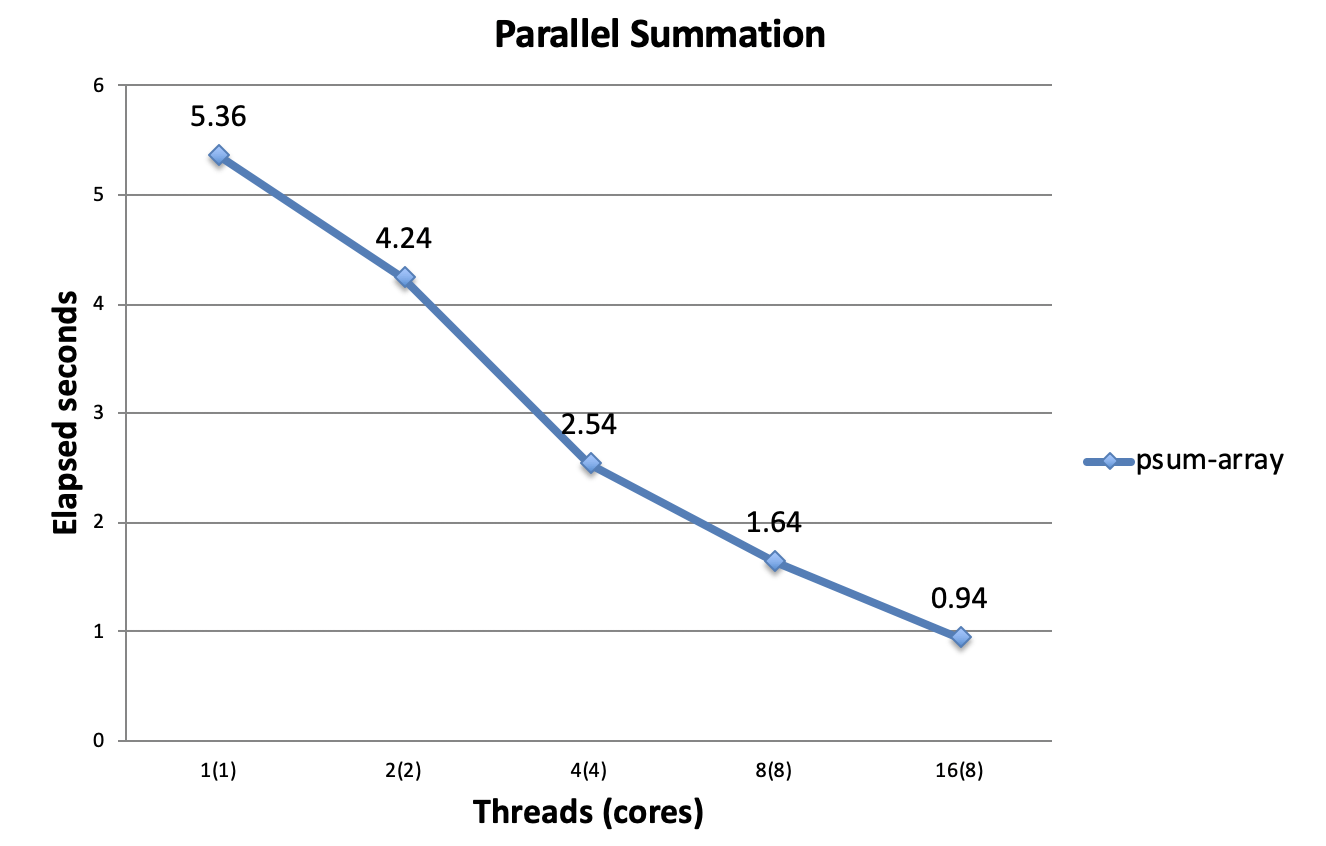
该多线程程序的性能开始超过单线程版本了,但是提升幅度并没有与核心数成正比。下一个版本改进内存的访问,将结果暂时放在寄存器而不是内存中。
/* Thread routine for psum-local.c */
void *sum_local(void *vargp)
{
long myid = *((long *)vargp); /* Extract thread ID */
long start = myid * nelems_per_thread; /* Start element index */
long end = start + nelems_per_thread; /* End element index */
long i, sum = 0;
for (i = start; i < end; i++) {
sum += i;
}
psum[myid] = sum;
return NULL;
}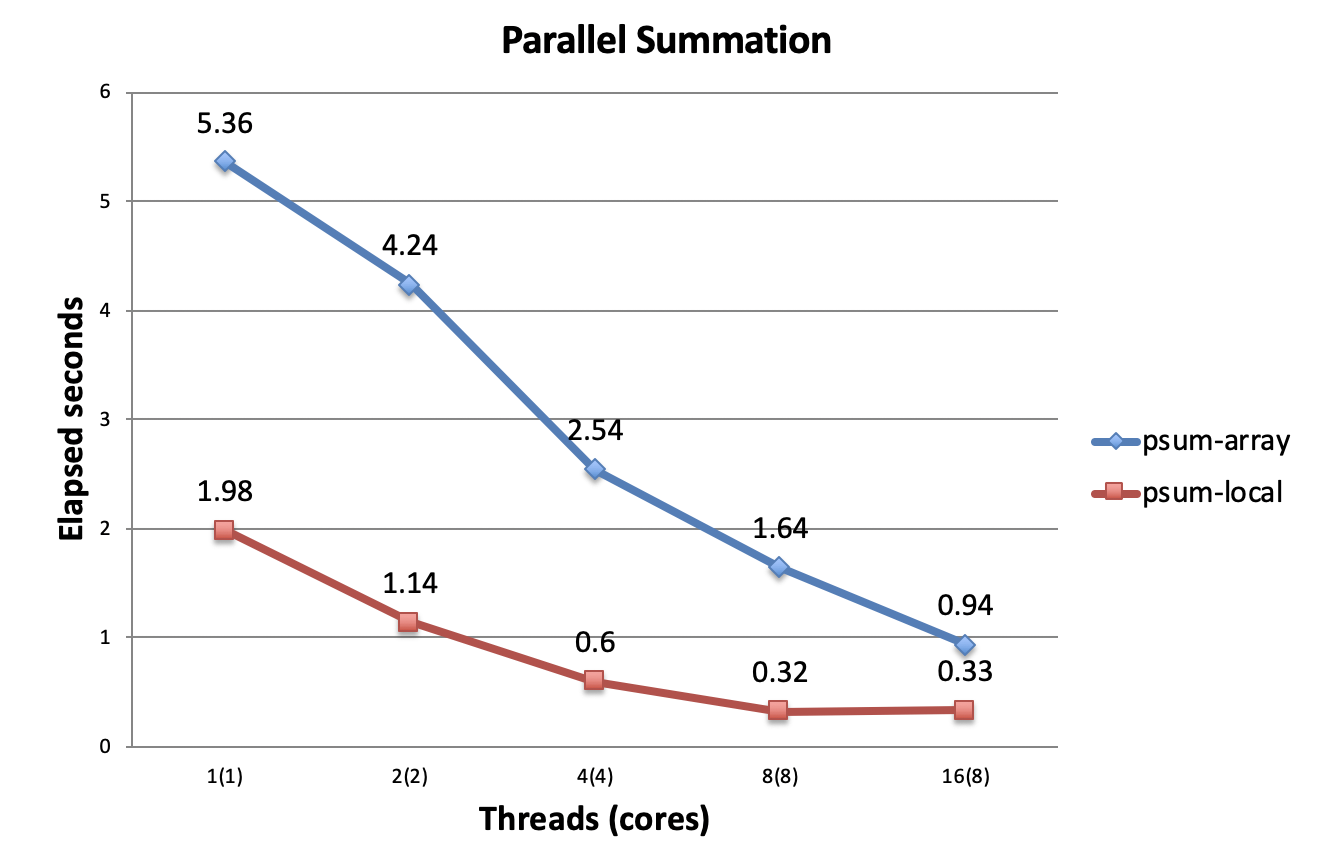
这个版本的多线程性能才基本符合多核心理论上带来的效率提升。求和是最容易优化的程序之一,大部分程序的优化是很难的。可见,多核心并不必然带来效率提升。多线程的性能也非常依赖程序的写法。